В исследованиях ассоциативных полей значительное место занимают разнообразные сопоставления. Например, могут сопоставляться ассоциативные реакции мужской и женской выборок, групп испытуемых, придерживающихся разных политических ориентаций и т.д. Основное место в таком сопоставлении должно принадлежать, безусловно, качественному, неформальному анализу. Однако, чрезвычайно желательным представляется использование и количественных показателей. В данной работе рассматриваются некоторые возможные пути количественного анализа в исследованиях такого рода и некоторые трудности, возникающие при этом в одной из областей возможного использования количественных методов.
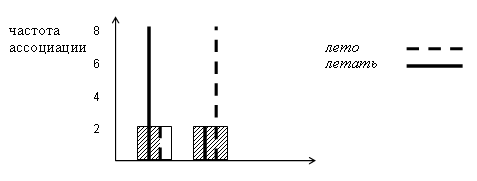
В свое время Дж. Диз предложил метод количественной оценки близости ассоциативных полей различных стимулов (Deese 1965). Предложенный им показатель отражает степень «пересечения» распределений ассоциативных реакций испытуемых на два стимула. Следующий пример и иллюстрация на Рис. поясняют суть дела.
Пусть десять испытуемых дают ассоциации на стимульные слова птица и бабочка. Допустим, что на стимул птица восемь из них ответили летать и два — лето, а на стимул бабочка, наоборот, — восемь ответили лето и два — летать. На Рис. длины сплошных (для летать) и пунктирных (для лето) линий показывают эти частоты.
На этом рисунке мы видим, что участки, где «короткие» линии накладываются на «длинные», заштрихованы. Это зоны наложения. Чем ассоциативные поля ближе, тем большую долю будут занимать, в общем, эти зоны наложения относительно длины линий, тем больше распределения ассоциаций на стимулы (используем термин теории множеств) «пересекаются».
Представляется целесообразным применить этот способ и для оценки близости распределений ассоциативных реакций на один и тот же стимул, получаемых от различных выборок испытуемых. При таком использовании «снимаются» проблемы учета случаев, когда два стимула вызывают друг друга в качестве ассоциаций, и нам нет нужды полагать, вслед за Дизом, что каждый стимул вызывает не одну, а две ассоциации — ту, которую испытуемый реально произносит и себя самого.
А те возможности, которые мы можем получить, используя такой показатель, увидеть нетрудно. В частности, одной из основных задач, которая может решаться с его помощью, является сравнение ассоциативных полей разных слов по степени расхождения ассоциаций различных групп испытуемых.
Формула для расчета этого показателя выглядит следующим образом:
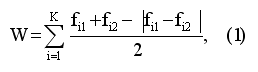
где:
W — показатель близости между 1-й и 2-й группами испытуемых;
К — общее число различных ассоциаций в обеих группах;
fi1, fi2 — частоты i-той ассоциации в первой и второй группах.
В том случае, когда численности выборок различаются, частоты необходимо нормировать, поделив их на численности выборок. В этом случае формула приобретает вид:
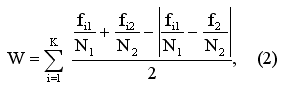
где:
N1 и N2 — численности 1-ой и 2-ой выборок
Арифметические действия, приводящие к нахождению слагаемых в формулах (1) и (2) можно заменить операцией, проще которой трудно что-либо себе вообразить: если в двух выборках имеется одинаковая ассоциация, берем меньшую, среди этих двух выборок частоту (или долю) i, если ассоциация в одной из выборок отсутствует, берем нуль. Проиллюстрируем, с учетом этого, порядок вычисления по формуле 2 на искусственном упрощенном примере.
Допустим, что мы сопоставляем ассоциации на стимул книга двух выборок испытуемых; численность выборки 1 — 100; численность выборки 2 — 50. Получены следующие ответы:
В выборке 1 — интересная 40, газета 30, журнал 15, толстая 10, автор 5, журнал 4, читатель 1.
В выборке 2 — интересная 30, газета 10, автор 5.
Переводим частоты в доли, деля их на численности выборок. Получаем: в первой выборке: интересная 0,4; газета 0,3; журнал 0,15; толстая 0,1; автор 0,05; во второй выборке — интересная 0,6; газета 0,2; автор 0,1; журнал 0,08; читатель 0,02. Запишем теперь для удобства эти доли рядом в два столбца; справа, в третьем столбце меньшие из этих долей даны курсивом:
| Интересная | 0,4 | 0,6 | 0,4 |
| Газета | 0,3 | 0,2 | 0,2 |
| Журнал | 0,15 | 0,08 | 0,08 |
| Толстая | 0,1 | 0 | 0 |
| Автор | 0,05 | 0,1 | 0,05 |
| Читатель | 0 | 0,02 | 0 |
Для определения показателя W осталось только сложить значения в третьем столбце: W = 0,4 + 0,2 + 0,08 + 0,05 = 0,73
Как легко видеть, показатель W может меняться от 0 до 1; 0 соответствует отсутствию одинаковых реакций, 1 — полному совпадению распределению ассоциаций.
Рассмотрим использование этого показателя в ситуации, где, как нам кажется, применение количественных методов должно встретиться с наибольшими затруднениями — при межъязыковых сопоставлениях.
В октябре 1999 года в Таллинне была проведена экспериментальная часть исследования, посвященного специфике языкового сознания билингвов. Материалом исследования стали данные ассоциативного эксперимента с русско-эстонскими и эстонско-русскими билингвами. Эти данные сопоставлялись с данными «Русского Ассоциативного Словаря» и данными свободного ассоциативного эксперимента с монолингвами, родным языком которых является эстонский. Испытуемыми были жители Таллинна в возрасте от 18 до 30 лет, имеющие или получающие высшее образование.
Было опрошено 70 эстонских монолингвов и 70 билингвов, из них 14 — эстонско-русских и 56 русско-эстонских. Им были предложены 104 стимульных слова, широко используемые в межкультурных сопоставительных исследованиях, причем половина слов предъявлялась на эстонском, половина — на русском языке. Порядок предъявления менялся: часть испытуемых получали сначала стимулы на русском языке, другая часть — «эстонские» стимулы, потом «русские».
Возьмем в качестве «рабочего материала» ассоциативное поле глаза (silmad). Как представляется, это ассоциативное поле весьма показательно в отношении тех трудностей, которые возникают при попытке применения количественных методов в межъязыковых сопоставлениях. Ниже приведены полученные результаты и соответствующая статья из РАС.
Эстонские монолингвы:
Silmad - kurvad (печальные), naine (женщина) 2; peegel (зеркало) 2; ilus (красивый) 2; suu (рот) 6; tumedod (темные); vikerkest (радужная оболочка); hing (душа); pruunid (коричневые) 3; pilk (взгляд) 2; labinagelikus (пронизывающий); saravad (блестящие) 2; punnis (навыкат); pruun (коричневый); oo (ночь); ookull (сова); mustad (черные); sumedad («мягкие»); sinised (синие) 11; ma naen (видящие); uni (сон); nagu (лицо) 2; ilusad (красивые); nina (нос); pisarad (слезы); ripsmed (ресницы); rohelised (зеленые) 2; ilu (красота); varvilised (цветные); valgus (свет); sinine (синий)3; kallid (дорогие); пропуск; ilmekad (выразительные); sara (блеск); tarkus (ум); suured (большие) 2; silmad (глаза).
РАС:
Глаза - голубые 11; карие 9; красивые 7; зеленые 4; серые, синие, черные 3; бездонные, завидущие, лицо, навыкате, нос, смотреть, смотрят 2; большие, бы не смотрели; вино «Черные глаза», внимательные, глаз, глазн. яблоки, глупые, горят, два, души, Ева Браун, женщины, живые, заплывшие, зеркало, зеркало души, зрачок, искренность, как озера, коричневые, косые, красные, любимые, метель, мир, наглые, о многом говорят, обмороженные, озеро, открыты, открыть, очи, очки, плохие, правда, проплакать, сильные, слеза, смазан, твои, тревожные, усталые, черные с длинными ресницами, чужие, яркие, ясные.
Русско-эстонские билингвы:
Глаза — глубокие, выразительные, серые 2, черные, голубые 4, очки 2; зрение, глубина 2; очи 2; рот, косые, карие, зеленые 2; свет, характер, излучение, красота, лицо, душа, нос 2; синие, добрые, пропуск, интерес, ночь, мысль.
Silmad — голубой, красивые, suured 3 (большие), голубые 3, prillid (очки), suu (рот), helesinised (светло-синие), черное, черные 2, mustad, очки, душа, rohelised (зеленые); sinised (синие); ресницы, ilusad (красивые), blue, открытые.
Эстонско-русские билингвы:
Silmad — hing (душа), ilusad (красивые), suured (большие) 2, vesi (вода), nagu noobid, must (черный), sinised (синие), ripsmed (ресницы), nagemine (зрение), pilk (взгляд), голубые, (sugavad — глубокие)
Глаза — sugavus (глубина), sinised (синие).
Одна проблема, с которой мы сталкиваемся при попытке применить показатель W, связана с отсутствием некоторых категорий в одном из языков — в данном случае, в эстонском языке нет соответствий русским терминам «голубой» и «карий», (а это две самые частотные ассоциации на стимул глаза в РАС). Объединять ответы голубые и карие с ответами синие и коричневые, что заметно сблизит данные некоторых групп испытуемых, или нет? Сходные вопросы возникают в силу несовпадения метафор и неполного совпадения значений слов в разных языках.
Другая проблема связана с несовпадением грамматических категорий.1
В данном примере, при проведении расчетов, мы стремились учитывать все различия ответов, избегали что-либо объединять. Пожалуй, единственным исключением была трактовка как эквивалентных ответов навыкате в РАС (т.е. у русских монолингвов) и punnis (навыкат) у эстонских монолингвов.
Действительно, при переводе, столь тонкие оттенки значения учесть трудно. Так что приведенные ниже показатели близости едва ли не минимальны.
В Табл.1 представлены показатели парной близости W для всех пяти групп испытуемых (включая данные РАС). Как видно из таблицы, распределение ассоциаций русских монолингвов (РМ) характеризуется наибольшей близостью к распределению ответов русско-эстонских билингвов, отвечавших на «русское» стимульное слово (РЭБ(р)), несколько меньшим пересечением характеризуются их ответы с ответами русско-эстонских билингвов, реагировавших на «эстонское» стимульное слово (РЭБ(э)), еще более меньшим — с ответами эстонских монолингвов (ЭМ) и минимальным — с ответами эстонско-русских билингвов (отвечавшими на «эстонское» слово (ЭРБ(э)).
Распределение ассоциаций ЭМ несколько ближе к распределениям ответов на эстонский стимул на русский, хотя различие это незначительно. Ответы русско-эстонских билингвов ближе к ответам русских, чем эстонских монолингвов, но различие это заметно уменьшается при ответах на эстонский стимул и т.д. Как видим, показатель парной близости дает разнообразную и интересную информацию.
Определением показателей близости, подобных рассмотренному, конечно же, не ограничиваются возможности количественного анализа в сопоставительных исследованиях ассоциативных полей. Рассмотрим еще один очень простой способ анализа, подходящий именно для используемых здесь данных.
Одна из задач исследования, данными которого мы пользуемся — определить «положение» групп билингвов относительно двух групп монолингвов. В случае использования данных, полученных по методу свободного ассоциирования, это можно операционализировать следующим образом: сколько различных ассоциаций из зафиксированных у билингвов встречается в ответах одной группы монолингвов, но не встречается в ответах другой.
В Табл.2 представлены результаты такого подсчета. Как видим, среди ответов русско-эстонских билингвов, отвечавших на русское стимульное слово, ассоциаций, характерных только для русских и только для эстонцев поровну. С учетом того, однако, что стимульное слово было русским, а также того, что выборка ассоциаций русских монолингвов была больше, это равенство говорит скорее о весьма существенном влиянии культурно-языковой среды, в которой живут испытуемые-билингвы. Что касается других групп билингвов, то в их ответах специфически «эстонских» ассоциаций больше (в группе эстонско-русских монолингвов, ассоциации, характерные только для русских монолингвов вообще отсутствуют).
| РМ | ЭМ | РЭБ(р) | РЭБ(э) | ЭРБ(э) | |
|---|---|---|---|---|---|
| РМ | 0,222 | 0,338 | 0,3 | 0,11 | |
| ЭМ | 0,222 | 0,2611 | 0,25 | ||
| РЭБ(р) | 0,338 | 0,088 | |||
| РЭБ(э) | 0,391 |
| РЭБ(р) | 6 | 6 |
|---|---|---|
| РЭБ(э) | 2 | 3 |
| ЭРБ | 0 | 3 |
1 Очевидно, что не только при межъязыковых сопоставлениях многое может определяться произволом исследователя. Например, он может посчитать эквивалентными все ассоциации, в которых так или иначе назван какой-либо цвет
2 В первом столбце — количество ответов встречающихся в отвтеах русских монолингвов, но не встречающихся у эстонских монолингвов. Во втором — количество ответов, встречающихся у эстонских монолингвов, но не встречающихся у русских монолингвов.